一种基于重构原型和生成学习的零样本语音情绪识别方法
1.本发明属于语音信号情绪识别领域,特别是涉及一种基于原型重构和生成学习的零样本语音情绪识别方法。
背景技术:
2.语音情绪识别(speech emotion recognition,简称ser)在人机交互等领域有着广泛的应用背景,可以通过研究语音信号中的情绪信息,判断说话人在语音段中所需要传达的主观意图,以及说话人更深层次的情绪表达。除此之外,还能够通过分析语音中的情绪信息,针对语音信号进行情绪表达的语音合成。在心理疾病诊断方面,可以通过相关技术实现对抑郁症等病人的初步筛查,并为进一步诊断和治疗提供依据;在虚拟现实方面,能够使得机器人具有更强大的情绪分析和表达能力。
3.与传统的语音情绪识别研究不同,零样本语音情绪识别专注于通过机器学习自主识别语音中看不见的情绪,使机器能够在不知道任何情绪状态样本的情况下感知未知的情绪语音。零样本语音情绪识别通过外部知识的信息传递,为机器自主感知情绪信息提供了可能,有助于基于音频的自主情绪计算。
4.公开的零样本语音情绪识别方案中,例如公开文献:xu x,deng j,cummins n,et al.exploring zero-shot emotion recognition in speech using semantic-embedding prototypes[j].ieee transactions on multimedia,2022,24:2752-2765.,主要存在以下两点不足:首先,现有的工作采用了直接从辅助模态中获得的原始原型,这可能导致语音和辅助模态之间的领域差距;其次,大多数策略研究了从已知域到未知域分类器的信息传递,没有充分考虑语音数据的变化特性。
技术实现要素:
[0005]
针对现有技术中直接采用原始原型导致语音信号副语言特征和辅助模态之间存在差异,以及现有大多数策略没有充分考虑语音数据的变化特性的问题,本发明提出一种基于重构原型和生成学习的零样本语音情绪识别方法。
[0006]
为解决上述技术问题,本发明采用以下技术方案:
[0007]
一种基于重构原型和生成学习的零样本语音情绪识别方法,包括数据获取步骤、模型优化和应用步骤;
[0008]
数据获取步骤,首先建立语音情绪数据库,其中包括若干语段样本,每个样本有其对应的情绪类别标签;将语音情绪数据库划分为已知情绪类别样本所组成的训练集,以及未知情绪类别样本所组成的测试集;每个样本都拥有已知且唯一的情绪类别标签。
[0009]
模型优化和应用步骤,包括顺序执行以下步骤:
[0010]
步骤一、提取生成nf维原始特征:对训练样本集中的每个语段样本,分别经过处理,提取出对应的副语言特征,作为原始特征,并对原始特征做规整化处理,得到n
(s)
个训练样本对应的规整化特征
[0011]
步骤二、对已知情绪类别名称进行语义嵌入映射,生成各已知情绪类别语义嵌入原型其中c
(s)
为已知情绪类别数,na为情绪类别名称的语义嵌入维数;
[0012]
步骤三、由从已知情绪类别语段样本提取的规整化副语言特征x
(s)
及其对应样本的情绪类别标签以及已知情绪类别原型a
(s)
,进行原型重构模型训练,得到已知情绪类别语段样本重构原型和最优原型重构模型,进而使用最优原型重构模型,结合未知情绪类别语义嵌入原型得到未知情绪类别语段样本重构原型
[0013]
步骤四、使用从已知情绪类别语段样本提取的规整化副语言特征x
(s)
及其对应样本的情绪类别标签y
(s)
,以及已知情绪类别语段样本重构原型进行生成学习,通过训练生成器fg(
·
)和判别器fd(
·
,
·
),求解得生成器对应的最优生成学习模型进而使用最优生成学习模型,结合未知情绪类别重构原型生成得到未知情绪类别生成样本的副语言特征;
[0014]
步骤五、将未知情绪类别生成样本的副语言特征经过步骤一中所述规整化处理后,送入分类器进行训练,求解得最优分类器,进而针对未知情绪类别测试语段样本提取副语言特征,并使用步骤一所述规整化方法,得到未知情绪类别测试语段样本的规整化副语言特征x
(u)
,并使用最优分类器进行分类判决。
[0015]
进一步的,步骤一中的规整化处理的方法如下:
[0016]
规整化前的所有语段样本中的任一样本的特征列向量为x
(0)
,其中n
(s)
个已知情绪类别训练样本的特征列向量组成的训练样本集为设为的第j个特征元素;
[0017]
对于任一样本的特征列向量x
(0)
,特征j对应元素的规整化处理的计算公式为:
[0018][0019]
其中表示x
(0)
第j行中最大的元素,表示x
(0)
第j行中最小的元素;x
·j为规整化处理后的结果;
[0020]
将任一样本中的所有的元素按照式(1)进行计算,得到任一训练或测试样本规整化后的特征列向量x=[x
·1,x
·2,...,x
·n]
t
,其中,属于已知情绪类别训练样本集的语段信号样本的
规整化后的特征向量组成训练样本的规整化特征向量集
[0021]
进一步的,步骤二中所述语义嵌入映射可通过对情绪类别名称使用词向量预训练模型实现:
[0022]
对于每个情绪类别,使用senticnet5模型中给出的最近5个相邻词来表示该情绪,其次通过输入预训练fasttext模型,获得这些相邻词的语义嵌入,并平均每个情绪状态对应的5个相邻词语义嵌入,作为该情绪类别的语义嵌入原型。
[0023]
通过上述方式向senticnet5和fasttext模型输入情绪类别名称,得到该类别对应的na维的情绪类别语义嵌入原型。对训练集对应的已知情绪类别,各类别的语义嵌入原型表示为对测试样本集中待预测的c
(u)
个未知情绪类别,各类别的语义嵌入原型表示为
[0024]
进一步的,步骤三中所述最优原型重构模型为
[0025][0026]
其中,ψ(
·
)表示原始原型上的原型重构映射,j(
·
,
·
)表示两个参数之间对应列的对齐损失函数,通过线性ν-支持向量回归(ν-support vector regression,简称ν-svr)实现;为已知情绪类别范例;线性映射矩阵通过主成分分析(principal component analysis,简称pca)对可见情绪样本进行线性降维;针对第c个已知情绪类别,使用列向量和n
c(s)
个该已知情绪类别样本的规整化副语言特征得到第c个已知情绪类别的中心作为各已知情绪类别范例。
[0027]
对已知和未知情绪类别语义嵌入原型a
(s)
和a
(u)
,使用最优原型重构模型分别得到已知和未知情绪类别重构原型和根据已知情绪类别语段样本标签y
(s)
,将分配给对应的已知情绪类别语段样本,得到各已知情绪类别语段样本对应的已知情绪类别重构原型
[0028]
进一步的,步骤四中所述生成器fg(
·
)用于学习最优生成学习模型,并根据任意情绪类别重构原型,得到相应情绪类别生成样本的副语言特征。设任一已知情绪类别重构原型其网络结构为:
[0029][0030]
其中,f
g1
(
·
,
·
)为第一层的输出,其公式为:
[0031][0032]
其中,nq维噪声q服从正态分布,relu(
·
)和leakyrelu(
·
)分别是修正线性单元(rectified linear unit,简称relu)和leaky relu激活函数,和表示生成器网络的线性权值,和是对应的偏置,隐藏层包括ng个节点。
[0033]
进一步的,步骤四中所述判别器fd(
·
,
·
)用于区分x
(s)
中任一已知情绪类别的语段样本或生成样本副语言特征x
(s)
,及对应的重构原型其公式为:
[0034][0035]
其中,f
d1
(
·
,
·
)为判别器隐藏层的输出,其公式为
[0036][0037]
其中和表示为判别器网络的线性权值,b
d1
和b
d2
为相应的偏差,隐藏层中使用nd个节点。
[0038]
进一步的,步骤四中所述最优生成模型求解中,包括对生成器和判别器的训练,使用的损失函数为:
[0039][0040]
其中,权重λ3>0;表示已知情绪类别生成样本的副语言特征在对应标签下的分类错误率,表示已知情绪类别c
(s)
ng个生成样本的已知情绪类别标签(每个类别ng生成样本)。cls(
·
,
·
)为在已知情绪类别语段样本x
(s)
上训练的softmax分类器,使用负对数似然(negative log likelihood,简称nll)损失。
[0041]
wasserstein生成对抗网络(wasserstein generative adversarial network,简称wgan)损失l
wgan
使用wasserstein生成对抗网络梯度惩罚(wasserstein generative adversarial network-gradient penalty,简称wgan-gp)损失:
[0042][0043]
其中已知情绪类别真实样本特征已知情绪类别生成样本特征权重λ1>0用于平衡真实数据与生成数据之间的关系,已知情绪类别合成样本特征权重λ2服从0-1均匀分布。
[0044]
进一步的,步骤五中所述分类器可采用任意监督学习分类器,所述监督学习分类器优选为softmax分类器或支持向量机(support vector machine,简称svm)分类器。
[0045]
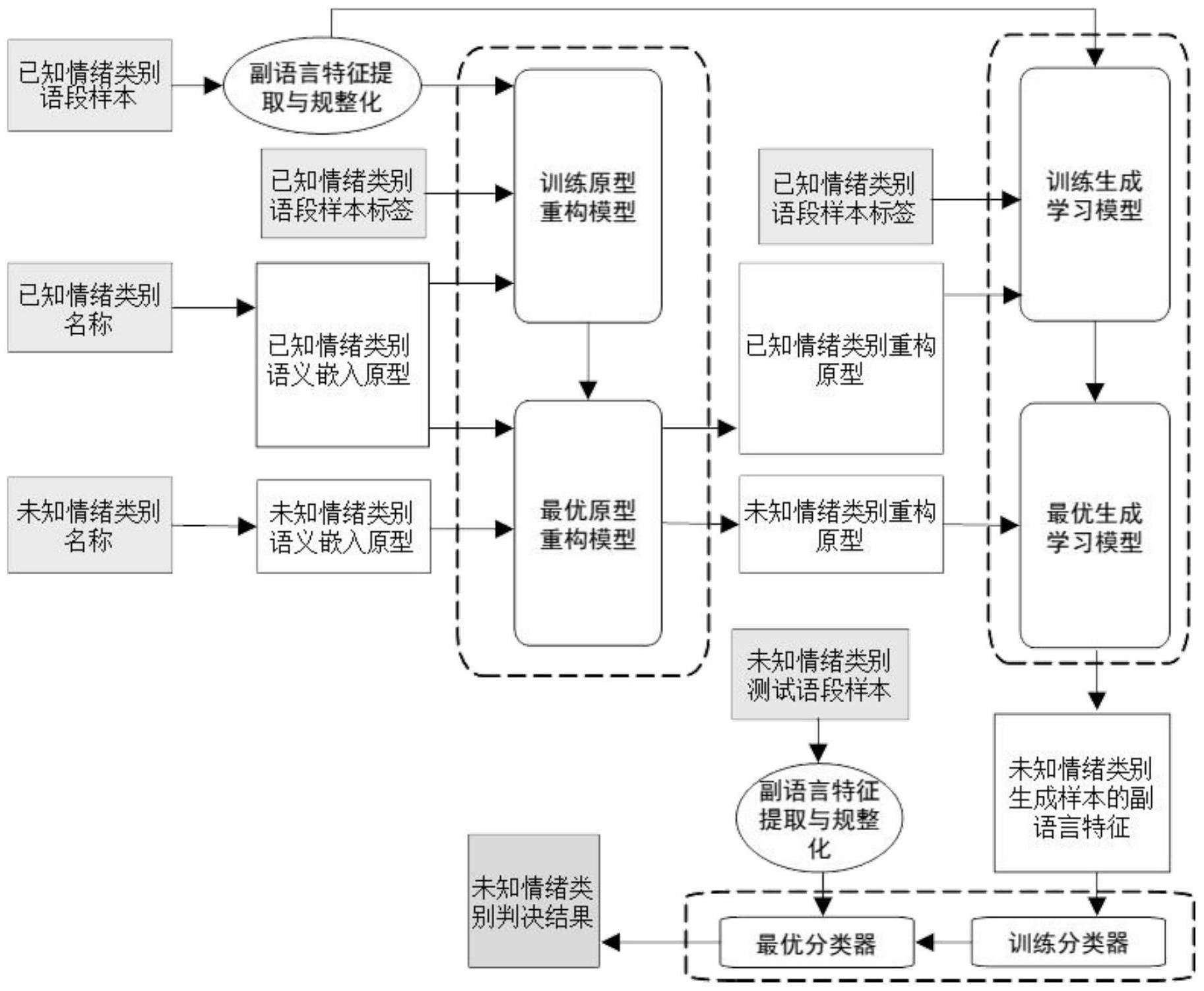
有益效果:如图1所示,本发明给出的一种基于原型重构和生成学习的零样本语音情绪识别方法,通过对语义嵌入原型的重构以及对未知情绪类别语段样本副语言特征的生成,实现了对带有未知情绪状态信息的语段信号样本,进行未知情绪类别的分类判决。具体地,在原型重构阶段,对已知情绪类别语段样本提取副语言特征,结合已知情绪类别语义嵌入原型、已知情绪类别语段样本标签,训练得最优原型重构模型,再结合已知和未知情绪类别语义嵌入原型,分别得到已知和未知情绪类别重构原型;在生成学习阶段,对已知情绪类别语段样本提取副语言特征,进而根据已知情绪类别语段样本标签,结合已知情绪类别重构原型,训练得最优生成学习模型,再结合未知情绪类别重构原型,得未知情绪类别生成样本的副语言特征;在监督学习阶段,利用未知情绪类别生成样本的副语言特征,训练得最优分类器,对未知情绪类别测试语段样本进行未知情绪类别判决。
[0046]
现有的零样本语音情绪识别方法中,例如公开文献:xu x,dengj,cummins n,et al.exploring zero-shot emotion recognition in speech using semantic-embedding prototypes[j].ieee transactions on multimedia,2022,24:2752-2765.中存在两个问题:直接采用原始原型导致语音和辅助模态之间的领域差距,以及现有大多数策略没有充分考虑语音数据的固有变化的问题。因此,本发明给出的一种零样本语音情绪识别方法,采用基于重构原型和生成学习的方式,分别通过重构和语音信号域相匹配的原型,以及能够提供生成样本多样性的生成学习方法,实现零样本语音情绪识别,即利用已知情绪类别语段样本,实现对未知情绪类别语段样本的分类判决。
[0047]
通过实验证明,本发明在语音信号情绪识别方面,基于原型重构和生成学习提出了一种零样本语音情绪识别的方法,能够针对未知情绪类别的语音信号语段样本,有效地识别出其所属的未知情绪类别。
附图说明
[0048]
图1为本发明的一种基于原型重构和生成学习的零样本语音情绪识别方法流程图。
具体实施方式
[0049]
下面结合附图及具体实施方式对本发明作更进一步的说明。
[0050]
如图1所示,本发明方法在原型重构阶段,首先对已知情绪类别语段样本提取副语言特征并进行规整化,进而结合由已知情绪类别名称处理得到的已知情绪类别语义嵌入原型、已知情绪类别语段样本标签,对原型重构模型进行训练,求解得到最优原型重构模型,再使用该最优原型重构模型,对已知和未知情绪类别语义嵌入原型进行处理,分别得到已知和未知情绪类别重构原型;在生成学习阶段,利用已知情绪类别语段样本的规整化副语言特征、已知情绪类别语段样本标签、已知情绪类别重构原型,训练生成学习模型,得到最优生成学习模型,并使用最优生成学习模型,结合未知情绪类别重构原型生成得到未知情绪类别生成样本的副语言特征;在监督学习阶段,利用未知情绪类别生成样本的副语言特征及其对应的未知情绪类别标签,对分类器进行训练得到最优分类器,进而使用最优分类器,对未知情绪类别测试语段样本进行副语言特征提取及规整化后,得到对该语段样本的未知情绪类别判决结果。
[0051]
下面对通过实验的方法将本发明方法与现有零样本语音情绪识别方法进行不加权精度(unweighted accuracy,简称ua)识别率和macro f1-score指标的对比。
[0052]
实验采用demos(database of elicited mood in speech)数据库中的语音信号部分对本发明实施例的方法进行有效性验证。
[0053]
数据库用意大利语录制,共9697个样本,分属于68个说话人,其中包括23个女性。本次实验使用其中的8类情绪类别,具体为neutral(neu)、guilt(col)、disgust(dis)、happiness(gio)、fear(pau)、anger(rab)、surprise(sor)、sadness(tri);数据集按每两类情绪的所有样本作为未知情绪测试语段样本集,其他情绪类别样本作为已知情绪训练语段样本集,不同的样本类型组合方式有28种,因此,本次实验共进行训练测试28次。
[0054]
实验的原始副语言特征采用扩展的日内瓦简约声学参数集(extended geneva minimalistic acoustic parameter set,简称egemaps)作为特征集,原始特征维数nf=88,特征来源于结合高级统计函数(high-level statistic functionals,简称hsfs)的25个低级描述子(low-level descriptors,简称llds),以及时态特征和等效声级,经过专家选择得到特征集。具体的本次实验中采用opensmile工具箱提取这些特征。
[0055]
已知和未知情绪类别的语义嵌入原型使用na=300维的英语单词语义向量,这些原型基于senticnet 5模型和fasttext预训练模型得到。实验中的语义嵌入模型使用的是fasttext,该模型是使用基于common craw上训练的200万个单词向量。
[0056]
实验中,为了体现本发明方法的效果,用于进行比较的方法分别为:sse(semantic similarity embedding)、latem(latent embedding)、eszsl(embarrassingly simple zero-shot learning)、sync(synthesised classifiers)、exem(exemplarsynthesis)、fgn(feature generating network)、lisgan(lever-aging invariant side gan)的识别模型,同时还考虑随机选择1000个虚拟原型条件下的sync方法(记为“sync-rand”),进一步考虑exem方法在所有约简维度上的最佳结果(记为“exem-best”)。本发明的一种基于原型重构和生成学习的零样本语音情绪识别方法表示为:本发明方法(实施例1)。
[0057]
实验中对作为训练集的已知情绪类别语段样本,采用情绪类别独立的三折交叉验证进行最优参数选取,作为实施例1,具体的实施例1选取参数的范围为:正则化系数为{2-3
,2-2
,...,23},ν值为{2-8
,2-7
,...,20},核尺度参数为{2-4
,2-3
,...,24}。本发明实施例中,选取参数为:生成学习过程中,使用自适应矩估计(adaptive moment estimation,简称adam)优化算子,初始学习率为10-6
,最大训练轮数为30,批大小为64;在生成器和判别器中,ng和nd设置为4096,nq=312;对于cls(
·
,
·
)中的softmax分类器,设置其采用的adam优化算子初始学习率为10-3
,最大训练轮数为50,批大小为100;权重λ1和λ3分别设置为10和0.01,λ2则按照均匀分布随机选取;通过使用经过训练的生成器,每个未见情绪类生成ng=600个样本;对于生成的未见情绪类样本进行监督学习的分类器,其adam优化算子在25轮训练内的初始学习率设置为10-4
。
[0058]
得到demos数据库上使用这些最先进的零样本语音情绪识别方法的最优ua平均结果如表1所示。由表1可知,实施例1的本发明方法相比于其他相关的对比例方法,能够针对语音信号未知情绪的识别取得更好的ua性能和f1-score。
[0059]
表1
[0060] 采用方法uaf1-score
对比例1sse51.8
±
3.7-对比例2latem52.0
±
2.9-对比例3eszsl52.0
±
3.8-对比例4sync54.6
±
5.951.9
±
6.6对比例5sync-rand57.8
±
4.654.5
±
6.4对比例6exem54.3
±
6.052.4
±
6.8对比例7exem-best61.8
±
4.859.2
±
4.5对比例8fgn58.7
±
3.157.5
±
3.0对比例9lisgan59.6
±
2.858.2
±
2.7实施例1本发明方法63.9
±
2.762.5
±
2.4
[0061]
进一步的,为了调查采用exem-best、fgn、lisgan和本发明方法在各情绪类别识别方面的表现,给出每个情绪类别作为未知情绪类别时,在实验中的平均ua结果(%)比较,制成表2。由表2可知,与现有的原型重建和生成学习方法相比,本发明方法对于大部分情绪类别的识别,都具有更好的性能。
[0062]
表2
[0063][0064]
综上所述,本实施例1中所采用的本发明方法首先对语义嵌入原型进行原型重构,进而通过训练得到的最优生成学习模型,对未知情绪类别样本的副语言特征进行生成,最后通过监督学习进行针对未知情绪类别的分类器训练,在零样本语音情绪识别问题上得到了更优的性能。
[0065]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1